大家好,我是雪梨🍐鸭~
今天跟大家分享如何处理Crawled – currently not indexed (feed Urls)登录你的谷歌站长后台,点击coverage然后点击Crawled – currently not indexed
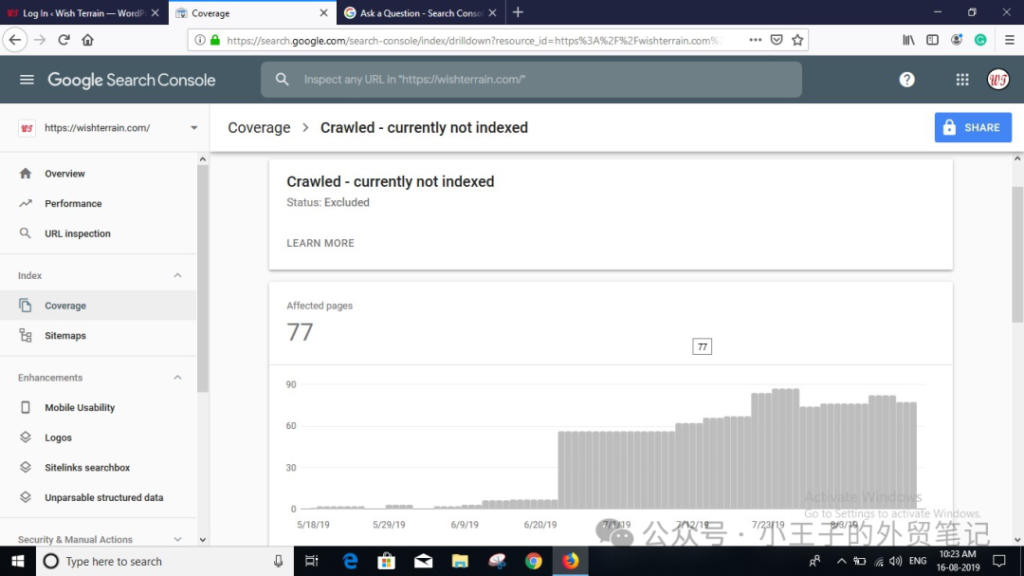
点开具体的url,不被indexed索引的原因有很多,有些可以不用处理。那我们看看具体哪些原因造成以及如何fix
1 feed

可以看到很多url是feed处理方式:“已抓取 – 目前未编入索引”表示 Google 尚未将 URL 放入“索引”中但它们是“feeds”,(feeds这个词我也不知道用中文怎么说,“提要”之类的意思)而不是网页webpage。所以一般来说无论如何feed都不应该出现在索引中,所以feed没有被收录是OK的,不用管就可以了。
2 图片链接
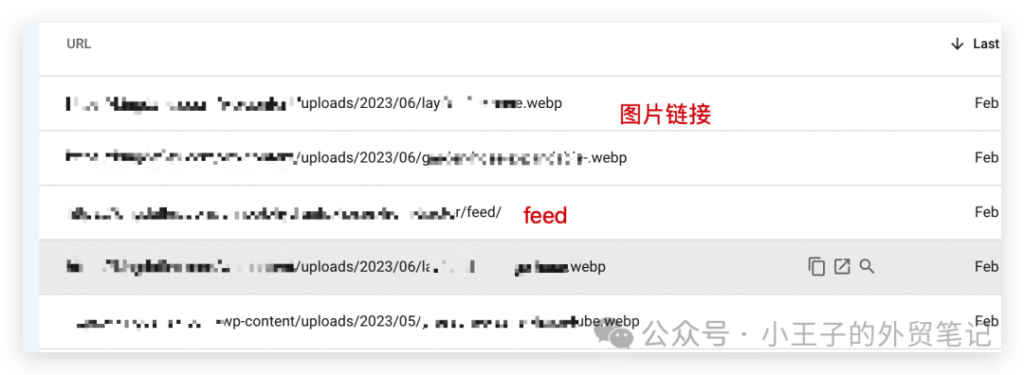
图片链接打开就是一张图片,什么内容也没有,不是网页内容webpage,也没有必要被索引。
3 内容分页
“已抓取 – 当前未编入索引”另一个极其常见的原因是与分页相关。
分页 URL 是在末尾带有代表页面的数字的页面,例如,www.mydomain.com/blog/page/2。我们经常会在该报告中看到大量分页 URL 的存在:
为了完整抓取网站内容,谷歌需要抓取分页 URL。这是谷歌获取网站内容的途径。然而,尽管谷歌使用分页作为访问内容的途径,但并不一定需要对分页 URL 进行索引。
这种情况不用处理。
4 内容薄弱以及低质
有时候我们会看到这份报告中的URL内容非常有限,甚至只是堆积了低质量的文字。这些页面可能已经正确设置了所有技术元素,甚至可能有正确的内部链接,但是当Google访问这些URL时,页面上的实际内容非常有限或质量低下,以至于Google认为它们没有太多用处。
如果你注意到“已抓取 – 当前未编入索引”中列出的大多数都是内容分页、RSS Feed以及其他内容非常稀少的杂项页面,那么你可以理解为这些页面并未为用户提供足够的价值,因此Google没有编入它们的索引也就可以理解了。如果确实是这种情况,那么你可以忽略这些页面。
但是,如果你看到你网站上很多重要页面(包含有价值/有用信息)被列在这里,那可能是整个站点范围内的质量问题影响了你的重要页面被编入索引。
优先级:高
解决方案:
作为网站所有者,你应该确保你的页面提供高质量的内容。检查它是否能够满足用户的意图,并在需要时添加高质量的内容。Google提出了一系列问题来帮助你确定内容的价值:
- 内容是否提供了原创的信息、报告、研究或分析?
- 内容是否提供了对主题的实质性、完整性或全面性描述?
- 内容是否提供了富有洞察力的深刻见解或有趣信息?
- 如果内容借鉴了其他来源,它是否避免了简单地复制或改写那些来源,而是提供了实质性的额外价值和原创性内容?
- 标题和/或网页标题是否对内容进行了非常实用的描述性总结?
- 标题和/或网页标题是否避免了夸大其词或耸人听闻?
- 您会将这种网页添加为书签、分享给朋友或推荐给他人吗?
- 您觉得这样的内容会出现在印制的杂志、百科全书或书籍中或被它们引用吗?
另一个需要关注的方面是优化网站上用户生成的内容。例如,假设您有一个论坛,有人问了一个问题。尽管将来可能会有很多有价值的回复,但在抓取时没有回复,因此Google可能会将页面归类为低质量内容。
此外,您还可以通过系统地从索引中删除低质量页面来提高整体站点质量。然而,网站质量并不是一夜之间就能改变的。谷歌需要一段时间来接收信号、重新处理和重新评估您的整体网站质量。
5 重复内容
“内容重复”指的是网站上存在相似或相同的内容,这可能发生在同一网站的不同页面之间,也可能发生在不同网站之间。内容重复可能对搜索引擎排名产生负面影响,因为搜索引擎通常倾向于提供多样性和独特性的搜索结果。
内容重复可以分为两种主要类型:
内部内容重复:发生在同一网站内的不同页面之间。这可能是因为网站有多个URL指向相同或几乎相同的内容,导致搜索引擎难以确定哪个页面是最相关的。
解决方法:使用规范标签(Canonical Tag)指定主要版本,确保内部链接指向规范版本,从而告诉搜索引擎哪个是原始内容。
外部内容重复:发生在不同网站之间,其中一些内容与其他网站上的内容相似或相同。这可能是意外的,也可能是恶意的抄袭行为。
解决方法:对于外部内容重复,网站所有者可以联系相关方,请求删除或修改重复内容。此外,通过提供原创和有价值的内容,网站可以在搜索引擎中获得更好的排名。
为避免内容重复问题,网站管理员可以采取以下措施:
- 创建独特的、有价值的内容,吸引用户和搜索引擎。
- 使用301重定向来将不同版本的URL指向主要版本。
- 在站点地图中只包含规范版本的页面。
- 定期监控Google Search Console以检测重复内容问题。
- 使用合适的规范标签来明确原始内容。
通过避免内容重复,网站可以提高搜索引擎排名,提升用户体验,并降低被搜索引擎降权的风险。
6 已抓取– 尚未编入索引” vs. “已发现– 尚未编入索引”

了解在Google Search Console中“已抓取– 尚未编入索引”和“已发现– 尚未编入索引”这两种状态之间的区别对于有效的SEO管理至关重要。
已抓取– 尚未编入索引:
这个状态表示Google的爬虫已经访问(抓取)了您的网页并分析了其内容,但最终决定不将其包含在搜索索引中。这个决定可能是由于各种原因,如内容质量、网站架构问题或页面不符合Google的指南。抓取过程意味着Google已经完全了解页面上的内容,但选择目前不在搜索结果中显示它。
已发现– 尚未编入索引:
另一方面,“已发现– 尚未编入索引”状态表示Google知道页面的存在,通常是因为URL在XML站点地图中被发现或从另一个站点链接过来。
然而,Google的爬虫尚未访问页面以抓取其内容。这可能是由于各种因素,如抓取预算限制或Google爬取队列中的积压。在这种情况下,Google需要更多关于页面内容的信息,只有在进行抓取后才能将其编入索引。
了解这些差异对于诊断和解决URL编入索引的问题至关重要。
对于标记为“已抓取– 尚未编入索引”的页面,重点应放在提升页面的内容和结构上。
对于状态为“已发现– 尚未编入索引”的页面,通常只需要等待Google的抓取。
然而,检查页面的可访问性并确保它包含在站点地图中可以加速这个过程。
以上。
如果有任何关于WordPress的问题以及建站咨询,欢迎大家随时沟通哦。